

Migration testing is to ensure that your application gets migrated from one system to another without affecting the legacy data and the functionalities. While the migration is in process, the testing team needs to ensure the integrity of the system is intact and that there is no data loss while migrating the data.
Data loss is the most common issue we come across in Migration Testing, and when we have huge data to be migrated we cannot completely depend on manual testing. Because it becomes impossible to verify content and compare it with the source data. If we have automation in place to check the vast amount of data, it will help us find data loss in less time and will give us more confidence in the migrated system.
Drupal 7 to Drupal 8 Migration
Let me share an example, we had a requirement to migrate a university site from Drupal 7 to Drupal 8. Since it was a university site it had heavy data/content including various courses, programs, staff, faculty, events etc. and we needed to ensure that all the data gets migrated with no data loss.
We had around 24 content types and each content type having thousands of nodes. It was impossible to verify this number of nodes manually. So we created an automation framework that helped us verify all nodes.
Our Tool Selection
We started exploring various options using existing functional tools like Behat, Selenium, Cypress, etc. but we wanted to avoid the browser interaction in this data verification process because visiting node pages and verifying data would require a lot of time and when it comes to 1000+ nodes it could take hours. Choosing functional tools which use browsers never suffice our needs when it comes to large amounts of data.
We Chose Drupal
Our source (D7) and destination (D8) were in MySql DB format, so we decided to create a custom tool to verify the data migration. We created a Drupal module having a custom Drush, command that would verify the migrated data. Helping us execute test fasters and at the same time utilise the existing drupal functionalities and its framework in our tool.
Our Approach
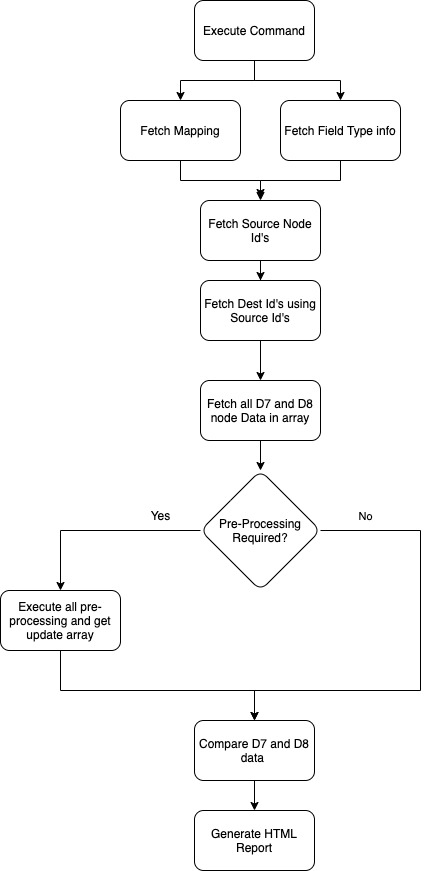
Creating Drush Command and Managing DB connections
We created the custom Drush 9 command - “drush migration:test <content_type_machine_name>”
The Drush command accepts two parameters - a content type name and the number of nodes to check, by default it would check all nodes.
Apart from this, we maintained two DB connections in the Settings.php file by adding another array for D7 - DB connection.
- Mapping Files
We required a few inputs before running the migration tests - we needed the information of each content type and its field mapping in D8. This helped us compare the data with the exact node and data inside each field.
We then created Mapping files in YAML format, each of these files was named in <content_type_machine_name>.yml format, each file had the following format:
The Fields array holds all the information about the fields from D7 to its corresponding D8 field and the Drush command uses these YAMLs as a source of input before querying the DB’s.
- Field Types Configurations
Each field type has specific columns in DB, and those particular columns were used to verify the data.
For example, each field having type text (we get this field type from a mapping file) will have a field table with column name as - <field_machine_name_value> as a column that will hold the actual data. We created field_type.yml which holds all the column information of each field type that will be used to fetch specific data for comparison.
Here the {fieldname} will get replaced with the actual field name from the mapping file. We had to maintain field type for D7 and D8 both because in D8 few column names were updated.
- Fetching all D7 and D8 Node values
To get the node data from the DB, we created a custom function that will dynamically create SQL queries based on mapping and config files for both D7 and D8 databases and fetch the values.
Since we have different naming conventions for tables in D7 and D8 we require to maintain the version name and change the prefix of the field table based on a version like D8 store field values in node_<field_name> and D7 stores in field_data_<field_name> same goes for storing node values D8 uses node_field_data table where D7 uses node table.
We used the fields option for mapping files and for each field, we use the field config file mentioned above to fetch the column of respective fields. Once all the tables and columns are collected we Command-Line built and executed the query on the respective database.
- Comparing Data and Generating HTML Report
Once the data for both D7 and D8 is fetched, both the sets of arrays were compared and failed nodes were logged in the reporter which then generated the HTML report after comparing all the nodes.
Reports
Reporting was important so all stakeholders could understand the reports and identify the issues mentioned in the reports. We created reports in 2 formats:
- Command Line - This was easy to understand and see the progress of test execution. It gives an overview of the number of tests that failed and passed and also provides a link to the HTML. report
- HTML Report - The HTML report had a detailed analysis of the test run, with all the information of failures and passed test cases.
- The Test Information section provided the basic information of the test and content under the test like content name, migration table, mapping file, etc.
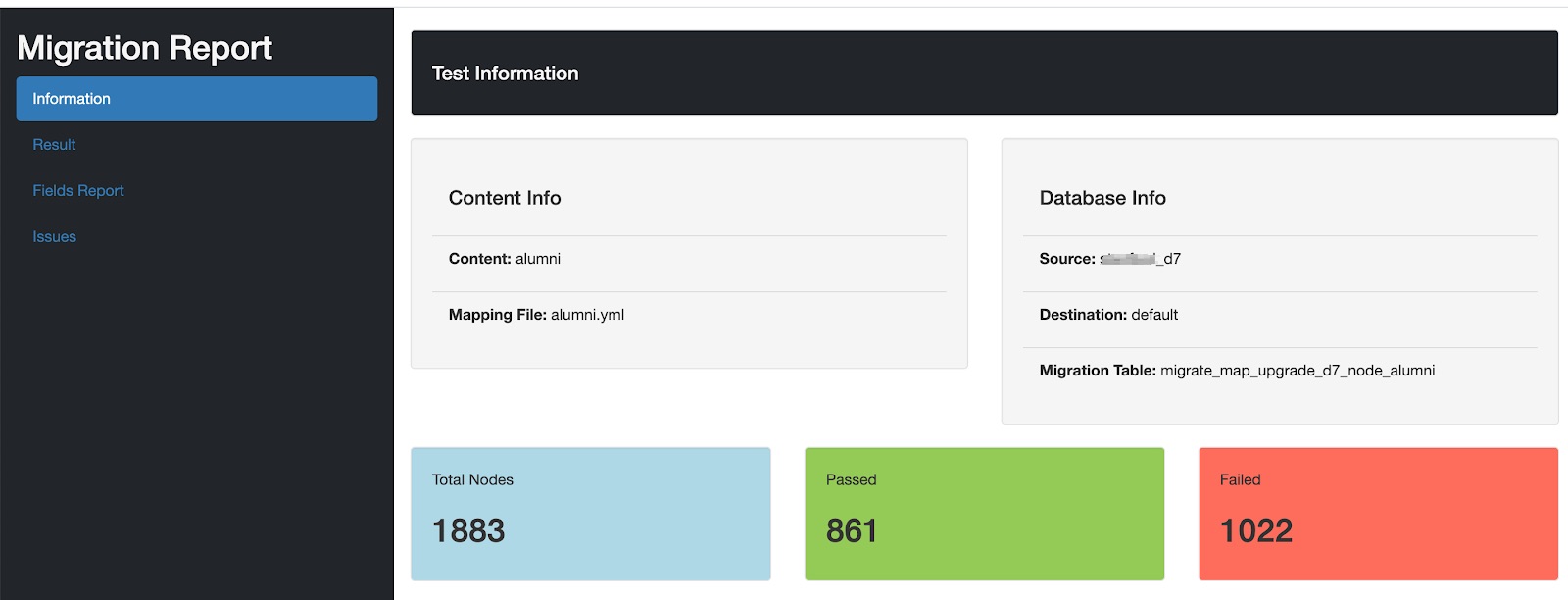
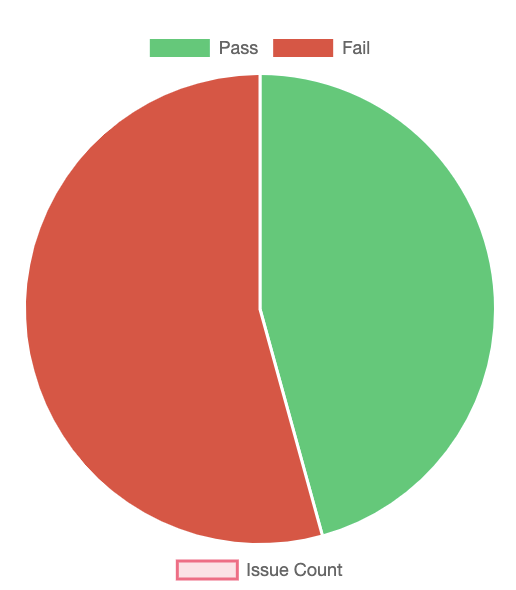
- The Result Section provided a pie chart with the exact number of pass and failures.
- The Fields Report Section highlights the fields’ columns that failed for a particular number of nodes.
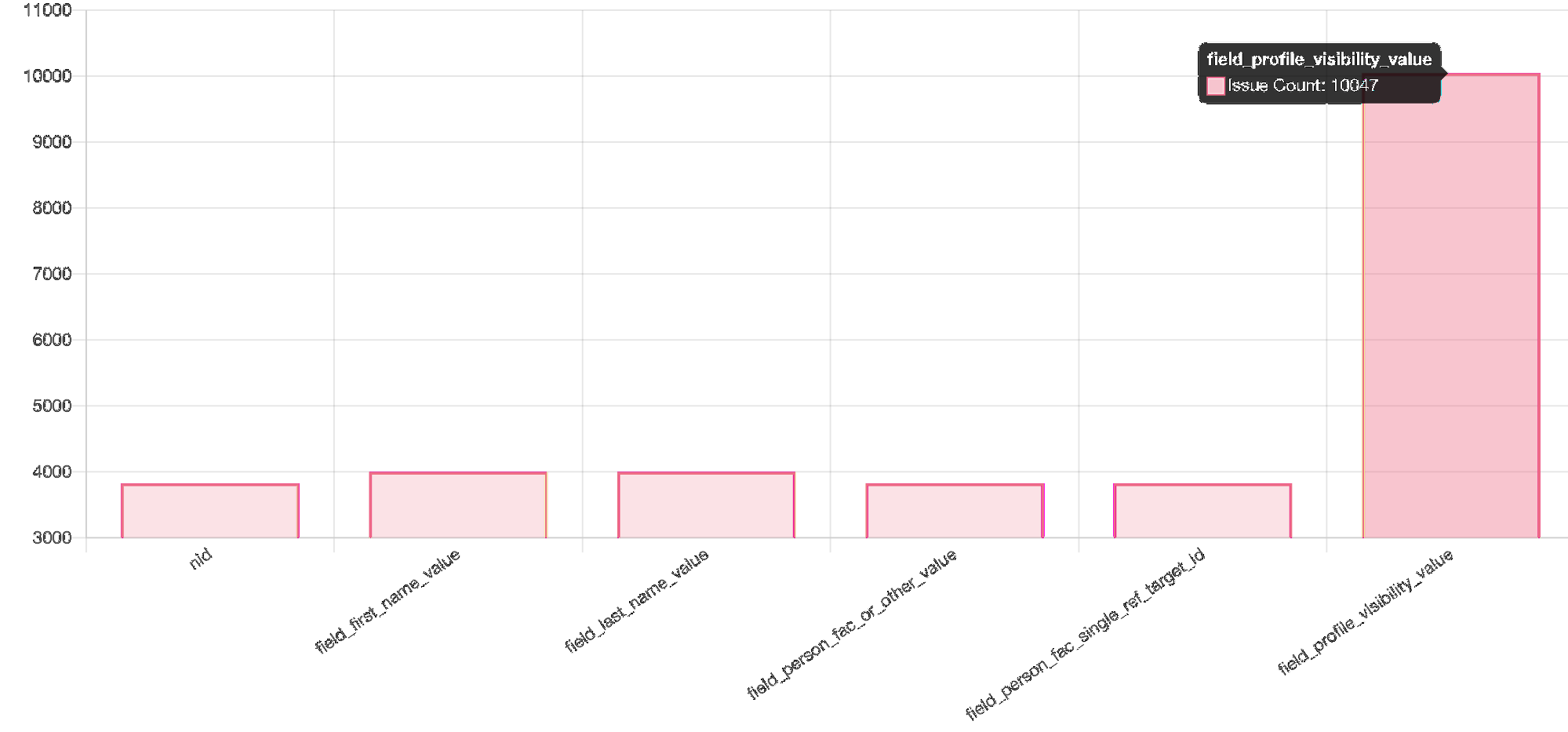
As shown in the above image, the profile visibility field has seen issues with around 10000+ nodes.
- Issues section - This shows the values that are missing or are not matching with the D8 migrated data.
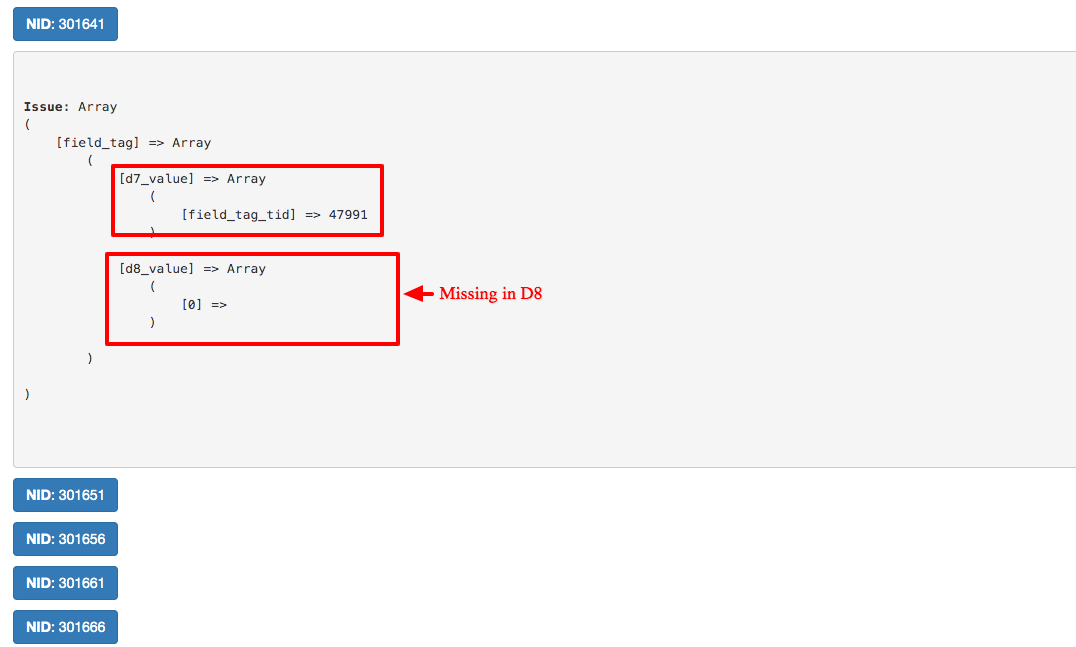

Referring to the above images - we can go through each node and verify the issue and compare the D7 and D8 values that are seen after migration. For example in the above image for field_tags, the tid is missing in D8 which means this tag was missing in the node after migrating it to D8.
Challenges
- False Positives
Because of the client requirements and changes in data format, there were various false positives. There were fields from D7 which were stored in different formats in D8. Following are a few examples:
- Boolean values 0 and 1 changed to true and false
- Date UTC timestamp got changed to other Date formats
- URL was prefixed in D8 as “internal:/”
- The Name field was getting divided into 2 fields First Name and Last Name
- Multiple fields were merged into 1 field
To handle such false positive scenarios we added one more step of preprocessing before comparing the D7 and D8 data. Prepossessing functions were called based on the field type, field name or content type.
The prepossessing class had all preprocessing functions based on the specific field type, field name or content type. These preprocessors updated the D8 data as per changes required and returned the values of the updated array.
Here’s an example of Link Preprocessing for one field:
- Field Collections to Paragraph Migration
D7 had a list of field collections that were used in nodes, these field collections were going to get merged as paragraphs in D8 and had around 44 types of field collections, which were directly mapped to paragraph fields. To handle this separately we directly verified field collections data with paragraphs using different Drush commands because the structure and way of storing data in field collections and paragraphs were different from normal fields.
So we created 2 YAML fields which stored a list of field collections fields and another for paragraph fields.
An example of FieldCollection.yml:
Example for ParagraphType.yml
As shown above, each field collection type had a paragraph type mapped and every field in field collection was mapped to fields in paragraph type. The rest of the process was the same as for nodes; only table and column prefix would be changed.
Demo
Outcomes
- We were able to find and fix more than 5000+ migration issues, which was difficult to find as part of manual testing.
- The creation of the test case was easy and quick, the user had to only create a mapping YAML file.
- Test execution was fast, we were able to test around 5000+ nodes in less than 10secs.
- Reduced the testing efforts and time is taken for testing.
- Good and readable reports helped all stakeholders to understand the issues.
- Dev-testing was easy and quick for developers, they were able to execute tests and identify bugs before passing them to the testing team.
- This framework can be reused and implemented for various content like taxonomy migrations, user migrations etc.
- Improved confidence of stakeholders in delivering huge data migration without data loss.